Contents
Benchmark results BSPonMPI 0.2 and a comparison
Currenlty the two leading BSPlib implementations are PUB and the Oxford BSP Toolset. The purpose and functionality of BSPonMPI differs from PUB or Oxford, just as PUB and Oxford differ. Therefore you should choose your BSPlib which fits your needs best. To get a feeling which implementation that would be, I ran some benchmarks.
The benchmark program is heavily inspired on the benchmark program written by Bisseling, which measures the worst case g (throughput) and l (latency). Bisselings benchmark program can be found in the BSPedupack package, which is available at his website. The source code of the benchmark programs is available here and here.
The benchmark program measures the latency and throughput using two different methods.
- Send each superstep one message to each processor. Let the message size vary
- Send each superstep a varying number of messages to each processors. Balance the communication
During the tests, Oxfords implementation proved to be the most challenging
competitor, when it uses bsp_put()only. Other situations are not
of interest, because the g differs one or more orders of magnitude in favor of BSPonMPI. See below for examples
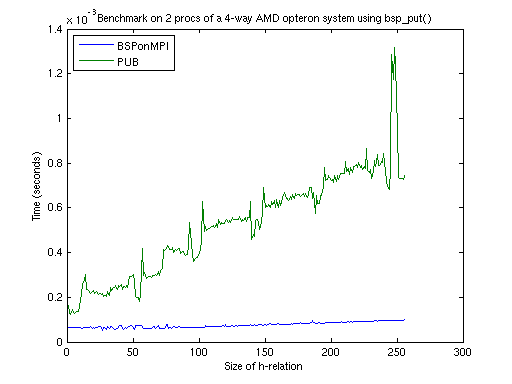
bsp_put() communication primitive. PUB version 8 was used and compiled as
shmem-release
Note:This difference between various communication primitives is not wanted. It makes predicting the running time of a BSP program complicated, because you have to deal with different g and l's. In fact: According to the BSP paradigm when calculating the running time of a BSP program you will have to pick the slowest l and g.
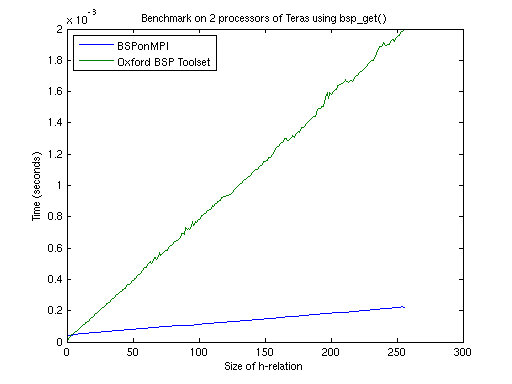
We now only consider Oxford BSP Toolset v1.4 using the bsp_put()
primitive. The benchmarks were performed on the two Dutch national
supercomputers at SARA: Teras and Aster. Teras is an SGI Origin 3800 on which
Oxford BSP Toolset v1.4 using native shared memory calls is installed. Aster is
an SGI Altix 3000 which has an MPI version of Oxford BSP Toolset v1.4.
Below the g and l are shown for Aster and Teras.
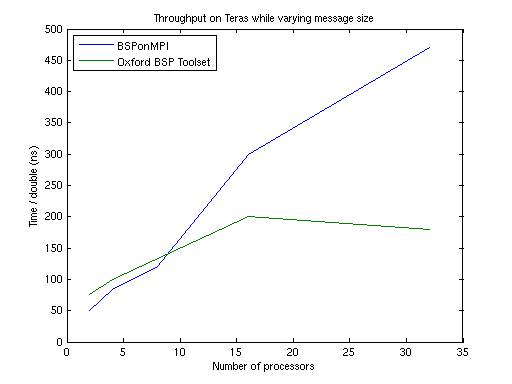
Teras


double (64 bit floating point value) to be delivered, i.e.: higher is worseThe latency increases much faster than the throughput decreases. Also note that the scale of the y-axes differ a factor 1000. One may conclude that latency becomes the most important factor when the number of processors grows. BSPonMPI is faster when the number of processors is 16 or more.
Aster
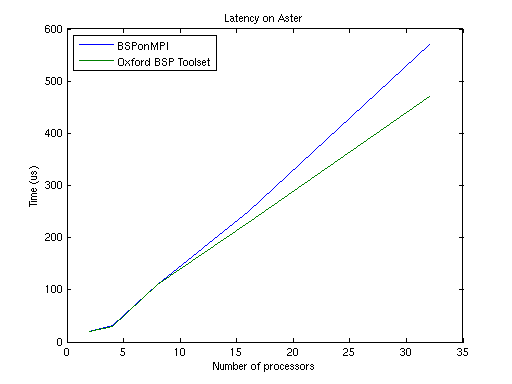
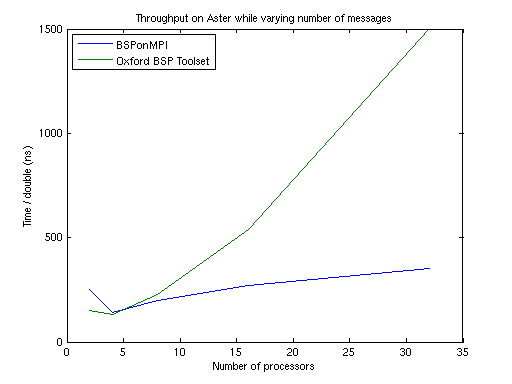
double (64 bit floating point value) to be delivered, i.e.: higher
is worse Now the latency increases much slower in comparison to the throughput. Although the time scales differ a factor 1000, the throughput becomes the dominant factor when the number of processors increases. From 16 processors on BSPonMPI is quicker when performing more than 50 puts
Measuring the throughput by varying the message size, only succeeded on Teras.
On Aster there wasn't a clear linear correspondence between message size and
communication duration.