BSPonMPI
0.2
BSPonMPI is an implementation of the BSPlib standard on top of MPI 1.1
You should read this document if you want to makes changes to BSPonMPI or if you want to write your own BSPlib implementation and you need some inspiration. If you just want to use BSPonMPI, you should read the README file (included with the BSPonMPI package) first. In all cases I assume that the reader is familiar with the BSPlib standard
This document contains
- A brief overview of the architecture of BSPonMPI
- Short descriptions of every function and data structure
- Detailed explanation of some non-standard (weird) solutions
- A lot of pictures and cross references
If you want to change something in BSPonMPI, you should read the Architecture description and the detailed descriptions of the code which will be affected by your changes. If you just need inspiration, you only need to read the Architecture description
The mission is to make a BSPlib implementation which will always be faster than the Oxford BSP Toolset on top of MPI and runs on all MPI enabled computer platforms. Until now this performance mission has not been achieved. BSPonMPI is still a bit slower when executing bsp_put() but it is faster on executing bsp_get() and bsp_send().
The BSPlib standard is designed to make programming using the Bulk Synchronous Parallel (BSP) model easier. The BSP model prescribes that you cut up your program in computation and communication supersteps. BSPlib helps you by providing a function bsp_sync() to execute an entire communication superstep. Communication is gathered during a computation superstep using three functions: bsp_put(), bsp_get() and bsp_send(). To put it very simple: A BSPlib implementation is a
Actually it is not that simple: A bsp_get() needs some action to be taken on the remote processor and expects some data to be returned. This very simple model can be repaired by seeing that there are not only data deliveries (bsp_put() and bsp_send()) but also data requests (bsp_get()). Therefore we may conclude that any BSPlib implementation consists of two buffers: one request buffer and one delivery buffer. Note that I ignore the two unbuffered communication routines bsp_hpput() and bsp_hpget(). These are currently implemented as their buffered counterparts.
Let me now restate what a BSPlib implementation is:
- Two communication buffers: One data request and one data delivery buffer.
- Three functions to fill them: bsp_get() which adds a request to the data request buffer, and bsp_send() and bsp_put() which add a delivery to the data delivery buffer.
- One function to empty them: bsp_sync()
The idea is to use the bulk communication procedures of MPI. The two most BSP like MPI functions are: MPI_Alltoall() and MPI_Alltoallv(). Nowadays computer manufacturers implement efficient MPI 1.1 libraries. Any MPI enabled machine has these functions and it is very probable that they are optimal. You may ask yourself why I don't use the DRMA procedures of MPI-2 . They may be very fast on DRMA enabled machines. However MPI-2 is not yet widely available and will therefore limit the use of this library.
In order to effectively use these communication procedures we need that the surrounding code is very fast and portable. The choices I made are
- Use ANSI C 99 as programming language in combination with the GNU autotools.
- Use an object oriented programming style.
- Collect all communication and transmit them using the least possible calls to MPI_Alltoallv.
- Use arrays to implement communication buffers. They can be used in a number of contexts, e.g. as a queue and as parameter of the MPI_Alltoallv() function.
- Allocate memory for these buffers only once (at the start of the program) and double the allocated memory if the buffer proves to be too small. Using this strategy the number of calls to malloc() remains very small.
- Minimise the use of branch statements (if, switch). I discovered this too late and I expect that more performance can be gained by rethinking the main data structure
- Try to make the optimising as easy as possible for a C compiler, but only use ANSI C constructions. Examples: restrict, inline, static, memory alignment, rather dereference a pointer than use memcpy(), etc...
Though I used ANSI C as programming language, I tried to program in an object oriented fashion. To translate classes and inheritance into C constructs, I used struct's, union's and enum's, e.g.: the C++ code class A { int x, y;};
class B: A { int a, b;};
class C: A { int c, d;};
void foo()
{
A a; a.x = 0;
B b; b.a = 1; b.x = 0;
C c; c.d = 2; c.y = 1;
}
typedef enum { B_type, C_type } class_type;
typedef struct { int a, b;} B_info;
typedef struct { int c, d;} C_info;
typedef union { B_info b; C_info c;} class_info;
typedef struct { int x, y; class_info info; class_type type;} A;
void foo()
{
A a; a.x = 0;
A b; b.type = B_type; b.b.a=1; b.x = 0;
A c; c.type = C_type; c.c.d=2; c.y = 1;
}
className_functionName( classref *, ...). For example class A
{
int x;
int foo() const
{
return x;
};
};
typedef struct {int x;} A;
int a_foo( const A * restrict a)
{
return a->x;
}
MPI_Alltoallv() function.
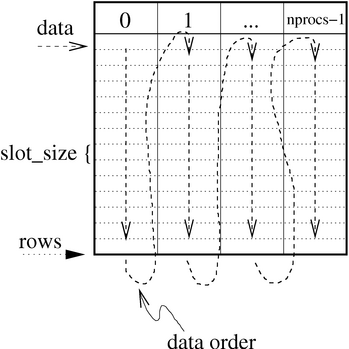
Data layout of the ExpandableTable data structure
Each column is again subdivided in slots. Accessing arbitrary bytes may be very expensive on some architectures or impossible. Therefore I try to use aligned addresses by subdividing each column in slots which are typically of the same size as a struct, double or something similar. The size of the entire array is equal to nprocs x rows x slot_size, where rows is the number of slots in a column. When data is added to a column the variable used_slot_count is incremented with the number of slots occupied by the new data. An example is shown below
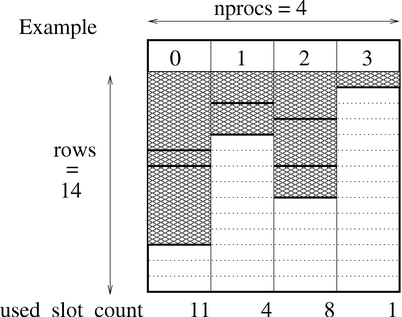
Example data layout of an ExpandableTable data structure
When one tries to add data to a column but there is not enough space available, new space is allocated. The new space is two times the size of the already allocated space. Again this array is subdivided in equally sized blocks. The old data is copied to the new locations and the new data is added. Note that the size of an ExpandableTable can only increase. This way only a very limited number of calls to malloc() are necessary. ExpandableTable and its member functions are declared in bsp_exptable.c and bsp_exptable.h
This data structure serves as a building block for the two communication buffers: RequestTable and DeliveryTable. They both have slightly different needs. RequestTable only has to handle data requests from other processors. Each data request is of a fixed size. Therefore implementing RequestTable will be rather straightforward. For details I refer to bsp_reqtable.h and bsp_reqtable.c. On the other hand DeliveryTable has to handle data deliveries which may differ in size. The implementation of DeliveryTable is a bit different; I use this buffer not only for communication of bsp_put(), bsp_send() and the data delivery part of a bsp_get(), but also for actions which have to be carried out during a bsp_sync(), e.g.: bsp_set_tagsize(), etc... for details see bsp_delivtable.h and bsp_delivtable.c
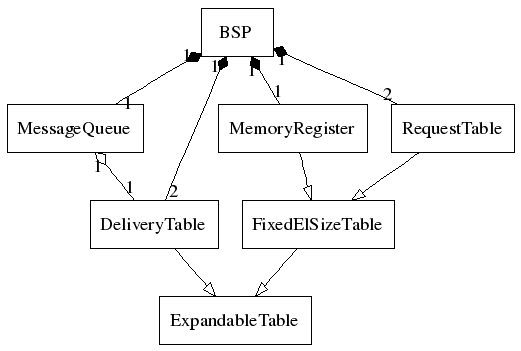
BSPlib also provides a way to address remote memory locations and a queue of received messages. These two are represented by the classes MemoryRegister and MessageQueue, respectively. MemoryRegister can also be modelled as a fixed size element array. Therefore the abstract class FixedElSizeTable is introduced. MessageQueue holds information where messages can be found in a received DeliveryTable. We get the following UML class diagram
A small UML legenda is shown below.
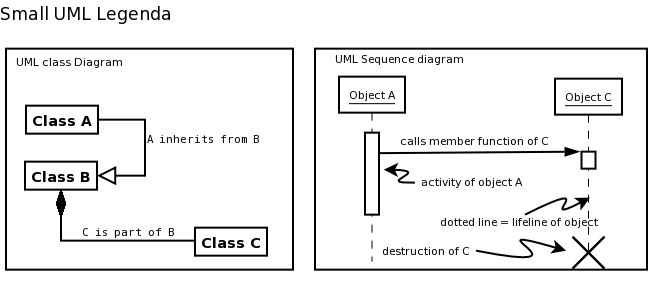
Legenda of UML class diagram and UML Sequence Diagram
Until now the explanation may still be a bit abstract. Below the source code and its sequence diagram of a simple BSP program are shown. It shows how processors and objects collaborate over time. #include <bsp.h>
#include <stdio.h>
void spmd_part()
{
int a=1, b=2, c=3;
bsp_begin(2);
bsp_push_reg(&a, sizeof(int));
bsp_sync();
if (bsp_pid() == 0)
{
bsp_put(1, &b, &a, 0, sizeof(int));
bsp_get(1, &a, 0, &c, sizeof(int));
bsp_send(1, NULL, "some text", 10);
}
bsp_sync();
bsp_pop_reg(&a);
bsp_sync();
bsp_end();
}
int main(int argc, char *argv)
{
bsp_init(&spmd_part, argc, argv);
printf("First perform some sequential code\n");
spmd_part();
printf("Finally perform some sequential code\n");
return 0;
}

Sequence diagram of the example above
There are still things which are not being taken care of in an optimal way. Ideas to improve performance are:
- Implement the memoryRegister_find such that it is O(1) in stead of O(n) (e.g. hash on least significant bits)
BSPonMPI. This is an implementation of the BSPlib standard on top of MPI. Copyright © 2006 Wijnand J. Suijlen
This library is free software; you can redistribute it and/or modify it under the terms of the GNU Lesser General Public License as published by the Free Software Foundation; either version 2.1 of the License, or (at your option) any later version.
This library is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public License along with this library; if not, write to the Free Software Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA
Generated on Sat Apr 8 20:12:25 2006 for BSPonMPI by
 1.4.6
1.4.6